The Grand Theft Auto series has come a long way since
the first opus came out back in 1997.
About 2 years ago, Rockstar released GTA V.
The game was an instant success, selling 11 million units over the first 24 hours and instantly smashing 7 world records.
Having played it on PS3 I was quite impressed by the level of polish and the technical quality of the game.
Nothing kills immersion more than a loading screen: in GTA V you can play for hours, drive hundreds of kilometers into a huge open-world
without a single interruption.
Considering the heavy streaming of assets going on and the specs of the PS3 (256MB RAM and 256MB of video memory) it’s quite amazing the game doesn’t crash after 20 minutes, it’s a real technical prowess.
Here I will be talking about the PC version in DirectX 11 mode, which eats up several GBs of memory from both the RAM and the GPU.
Even if my observations are PC-specific, I believe many can apply to the PS4 and to a certain extent the PS3.
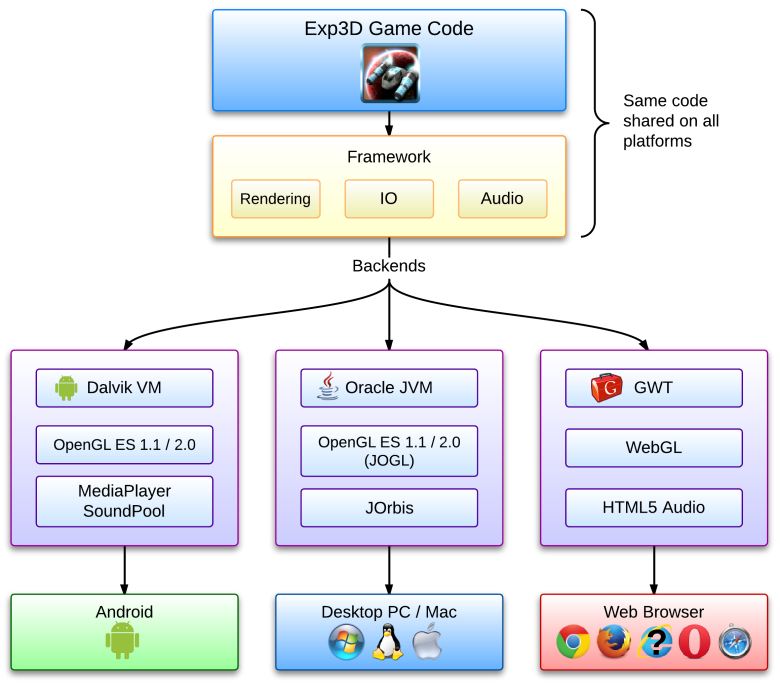
Dissecting a Frame
So here is the frame we’ll examine: Michael, in front of his fancy Rapid GT, the beautiful city of Los Santos in the background.

GTA V uses a deferred rendering pipeline, working with many HDR buffers.
These buffers can’t be displayed correctly as-is on a monitor, so I post-processed them with a simple Reinhard operator to bring them back to 8-bit per channel.
Update: HDR monitors are common nowadays, this was not the case when this article was written back in 2015.
Environment Cubemap
As a first step, the game renders a cubemap of the environment. This cubemap is generated in realtime at each frame,
its purpose is to help render realistic reflections later. This part is forward-rendered.
How is such cubemap rendered? For those not familiar with the technique, this is just like you would do in the real world when taking a panoramic picture:
put the camera on a tripod, imagine you’re standing right in the middle of a big cube and shoot at the 6 faces of the cube, one by one, rotating by 90° each time.
This is exactly how the game does: each face is rendered into a 128x128 HDR texture. The first face is rendered like this:
The same process is repeated for the 5 remaining faces, and we finally obtain the cubemap:
Cube seen from the outside

|
View from inside the cube
(Drag to change view direction)
|
Each face is rendered with about 30 draw calls, the meshes are very low-poly only the “scenery” is drawn (terrain, sky, certain buildings), characters and cars are not rendered.
This is why in the game your car reflects the environment quite well, but other cars are not reflected, neither are characters.
Cubemap to Dual-Paraboloid Map
The environment cubemap we obtained is then converted to a dual-paraboloid map.
The cube is just projected into a different space, the projection looks similar to sphere-mapping but with 2 “hemispheres”.
Why such a conversion? I guess it is (as always) about optimization: with a cubemap the fragment shader can potentially access 6 faces of 128x128 texels, here the dual-paraboloid map brings
it down to 2 “hemispheres” of 128x128.
Even better: since the camera is most of the time on the top of the car, most of the accesses will be done to the top hemisphere.
The dual-paraboloid projection preserves the details of the reflection right
at the top and the bottom, at the expense of the sides. For GTA it’s fine: the car roofs and the hoods are usually facing up, they mainly need the reflection from the top to look good.
Plus, cubemaps can be problematic around their edges: if each face is mip-mapped independently some seams will be noticeable around the borders, and GPUs of older generation
don’t support filtering across faces. A dual-paraboloid map does not suffer from such issues, it can be mip-mapped easily without creating seams.
Update: as pointed-out in the comments below, it seems GTA IV was also relying on dual-paraboloid map, except it was not performed as a post-process from a cubemap: the meshes were distorted directly by a vertex-shader.
Culling and Level of Detail
This step is processed by a compute shader, so I don’t have any illustration for it.
Depending on its distance from the camera, an object will be drawn with a lower or higher-poly mesh, or not drawn at all.
For example, beyond a certain distance the grass or the flowers are never rendered. So this step calculates for each object if it will be rendered and at which LOD.
This is actually where the pipeline differs between a PS3 (lacking compute shader support) and a PC or a PS4: on the PS3 all these calculations would have to be run on the Cell or the SPUs.
G-Buffer Generation
The “main” rendering is happening here. All the visible meshes are drawn one-by-one, but instead of calculating the shading immediately, the draw calls simply output
some shading-related information into different buffers called G-Buffer. GTA V uses MRT
so each draw call can output to 5 render targets at once.
Later, all these buffers are combined to calculate the final shading of each pixel. Hence the name “deferred” in opposition to “forward” for which each draw call calculates the final shading value of a pixel.
For this step, only the opaque objects are drawn, transparent meshes like glass need special treatment in a deferred pipeline and will be treated later.
G-Buffer Generation: 100%